

| ITEC 380 |
| 2008fall |
| ibarland |
|
|
|
home—info—lectures—exams—archive
update:
- If you turn in *all* of hw06 on Friday Dec.12, you'll get a 15% bonus to your score.
- Otherwise, you can turn in part on Friday Dec.12, and the whole project on the last day of Finals, Dec.18 (Thu) 17:00.
The part due Dec.12 is: all of L1 (parse, toString, eval), plus parse and toString for L2.
To turn in For turning in during finals week, just slip it under my door. (I prefer *not* being emailed solutions, but if you must, then create a single readable file (plain-text or pdf) and send that to me [*not* a zip with many source files]. You don't need to print out any code which is was provided to you (e.g. UtilIan), if you didn't modify it.)
For this project, we'll implement a “tower” of languages (L0, L1, L2, L3, and L4), each language incorporating more features than the previous. L0 is provided for you.
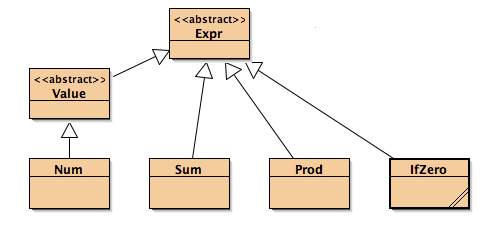
% L0 syntax:
% An Expr is one of:
Expr ::= Num | SumExpr | ProdExpr | IfZeroExpr
SumExpr ::= {plus Expr Expr}
ProdExpr ::= {times Expr Expr}
IfZeroExpr ::= {ifZero Expr Expr Expr}
|
 improved detection of certain errors, Wed. 19:30).
improved detection of certain errors, Wed. 19:30).
(20pts) L1 is just like L0, but with two additional types of expressions:
Expr ::= … | ModExpr | IfNegExpr
ModExpr ::= {mod Expr Expr}
IfNegExpr ::= {ifNeg Expr Expr Expr}
|
The only method which cares what these new expressions mean (their semantics) is eval: {ifNeg Expr0 Expr1 Expr2} first evaluates just Expr0; if that value is negative, then it evaluates Expr1 and returns its value; otherwise it evalutaes Expr2 and returns its value. (Note how you are making sure that ifNeg short-circuits.)
{mod a b} evaluates to3 a mod b, where the result is always between 0 (inclusive) and b (exclusive); in particular, the result is never positive if b<0. Notice that this is slightly different behavior than either Java's built-in % (which behaves differently on negative numbers), and from Scheme's built-in modulo (which only accepts integers). In Java, you can use a%b (if b>0 or a%b=0) and a%b+b (otherwise). In scheme or Java, you can use b*(a/b-floor(a/b))
Hint: Most all the code for this problem is virtually identical to existing code. The only exception (and it's a mild one) is the eval for ModExprs, since the formula is a bit more involved.
(40pts) L2 adds identifiers to L1:
Expr ::= … | Id | WithExpr
WithExpr ::= {with Id Expr Expr}
|
Update your three methods parse, toString (a.k.a. expr->string), eval. We now need to define the semantics of {with Id E0 E1}:
However, there is one wrinkle:
What if E1 contains some non-free (“bound”) occurrences of Id?
That is,
wat if E1 contains
a (nested) “{with x … …}”?
In that case the inner one should shadow the outer one:
{with x 3 {with x 5 {plus x 3}}} ⇒
{with x 5 {plus x 3}} ⇒
{plus 5 3} ⇒
8
Thus, when substituting,
only substitute “free occurrences” of an Id
in E1,
not any “bound occurrences”8.
Think through exactly what you need to substitute,
in the following examples:
{with y 3 {with x 5 {plus x y}}}
⇒
⇒
⇒
8
{with y 3 {with x y {plus x y}}}
⇒
⇒
⇒
6
{with x 5 {with y 3 {plus {with x y {plus x y}} x}}}
⇒
⇒
⇒
⇒
⇒
11
(You might find it helpful to draw the parse tree,
rather than staring at the flat string,
especially for this last example.)
Observe that when evaluating a (legal) L2 program, eval will never actually encounter an Id -- that Id will have been substituted out before we ever recur down to it.
(40pts) L3 adds functions and function-application to our language:
Expr ::= … | FuncExpr | FuncApplyExpr
FuncExpr ::= {fun Id Expr}
FuncApplyExpr ::= {Expr Expr}
|
Just like numbers are self-evaluating, so are FuncExprs. If evaluating (an internal representation of) a FuncExpr, just return that same (internal representation of) function. We won't actually evaluate the body until the function is applied.
In FuncApplyExpr, the first Expr had better evaluate to a function. (That is, it's either a FuncExpr, or it's an Id which gets substitued to a function value.) For example, here is a function for computing absolute value:
{fun x {ifNeg x {times -1 x} x}}
|
A funcApplyExpr represents calling a function. Here are two examples, both computing the absolute value of -5:
{{fun x {ifNeg x {times -1 x} x}} -5}
{with abs {fun x {ifNeg x {times -1 x} x}}
{abs -5}}
|
Observe that our programs can now evaluate to either of two types: numbers or functions. In Java, we'll need to have a class which can represent either, as the return type for our eval.
(35pts extra credit:
This problem and the next are really the crux of the assignment,
but due to the impending end-of-semester, it will be extra credit.)
Deferred evaluation:
L4 doesn't add any new syntax,
but it is a different evaluation model which
will give us more expressive semantics.
Use a new file/project for L4, separate from L0-L3.
There are two problems9 with the substitution approach used above: we can't make recursive functions, and it doesn't generalize to assigning to variables. We solve these problems with deferred evaluation:
Note that this gives us dynamic scoping.
1 To keep from getting bogged down in tokenizing input, Java implementations can use exactly those strings recognized by java.util.Scanner.nextDouble() (including NaN) and Scheme implementations can use exactly those strings recognized by number?, (including +nan.0, -inf.0, and 2+3i). ↩
2 For ease of implementation, we'll allow Java implementations to use floating-point arithmetic (doubles) instead of actual arithmetic. ↩
3 Because we don't need to check for bad inputs, it's fine to have your interpreter crash if b=0. ↩
4 Note that our different implementations are now varying by more than just precision of arithmetic: in a Java implementation, NaN is a Num, and in a scheme implementation it's an Id. We won't use any test cases involving such subtle differences. However, note how our choices in designing a new language are being influenced by the language we're trying to easily implement it in! This stems from the fact that a primary design constraint on L1 is that implementing an intepreter for L1 doesn't get bogged down in minutae when using either Java or Scheme. ↩
6
Okay -- if you implement the union data type of Exprs
by using the Strategy pattern, then you can regain
the simplicity of the functional approach
in this case.
5In particular, even if using Java, you'll want do the substitution using a functional approach: have a method which returns a new parse tree with the substitutions, rather than mutating the existing tree. The mutation approach leads to quite unwieldy code. (Try it, if you don't believe me 6 ↩
7 The notation “{with x 5 {plus x 3}} ⇒ {plus 5 3} ⇒ 8” is shorthand for
eval(parse("{with x 5 {plus x 3}}"))
= eval(parse("{plus 5 3}"))
= 8
|
8 nor any “binding occurrences”: The first x in {with x 5 {plus x 3}} is a binding occurrence, and the other x is a bound occurrence. (The variable is bound inside the scope of its binding occurrence.) ↩
9 A third issue, pointed out in Programming Languages and Interpretation, is that evaluating deeply nested withs is an O(n2) algorithm. ↩
10 Note that the list you recur with has the additional binding, but that recursive call shouldn't end up with any net change to your bindings. If you use lists which require mutation (viz java.util.List), you must either make duplicates before recurring, or be sure to remove your recently-added binding after your recursive call. ↩
home—info—lectures—exams—archive
| ©2008, Ian Barland, Radford University Last modified 2008.Dec.10 (Wed) |
Please mail any suggestions (incl. typos, broken links) to iba�rland |
 |